
If you have interviewed for a software engineering role, even graduate roles, you're very likely to come across system design interviews.
Though not as infamous as the algorithms & data structures interview, it's nonetheless just as difficult, if not more so. What's more, it's usually more important, as it often determines your level of seniority. Even if most engineers are aware of this, I'm seeing that they don't prepare as much for this type of interview. A big reason for this is because it's genuinely difficult to prepare - it requires a level of experience and working knowledge that cannot easily be learned from books.
This being said, the biggest mistake I see engineers making is not having a structure, a framework that guides their approach and decision making. As someone who has been on both sides in hundreds of system design interviews, I developed a framework that you can use to maximize your chances to succeed.
In this article, I want to share my approach using the classical question of designing a social media platform, such as Facebook or Instagram. I'm choosing this because it's well understood and it allows us to focus on the how not the what. To be more specific, we are going to focus on HLD (high-level design) here, as this is the most common type of system design I've seen in interviews. There is also LLD (low-level design), product design, or specific component/service design, but we will not discuss them in this article. Furthermore, this is going to be backend system design, as its what you will encounter the most.
Design Facebook - A 5-step process
As an interviewee, I applied a 5-step process to all my system design interviews. It helped me make sure I touched on all the relevant points while keeping track of the time. This assumes a normal 60-minute interview, where taking into account introductions and Q&A, usually leaves you with at most 50 minutes for the actual design.
Before going through each step, I want to stress something. Throughout the interview, you are expected to lead the discussion from start to finish. Everything that we are going to discuss in the next sections assumes you are the one asking questions, making proposals, motivating your choices and defending your ideas. Treat the interviewer as if they are the PM in the team with you being the tech lead that is responsible for coming up with the design.
1. Functional Requirements and Scope - 5-7 minutes
One of the most important skills as an engineer is the ability to build things that bring value to customers. The way you do this is by gathering the information needed by asking relevant questions and making good assumptions.
Treat the interviewer as your product manager and don't be afraid to ask a lot of questions. The interviewer might answer straight-up or might pass the ball back to you in order to make an assumption. Pay attention to these moments, as it's a signal the interviewer expects you to make informed assumptions without having to ask for every detail.
This first step is where I see candidates dropping the ball a lot. They rush through this part, don't ask enough clarifying questions and end up designing the wrong system. Try to find out what the interviewer wants you to build, not what you think should be built. Also bear in mind that you won't have time to design a system with a complex feature set in 5o minutes, so start from a few simple requirements instead of trying to do everything.
Let's apply this to our problem of designing Facebook. To have an MVP (minimum viable product) it's safe to start with the following assumptions of what a user of the platform can do:
- Post new content
- View, like and comment on posts
- Add friends
- See the profile of any user, including their posts
- See an aggregated timeline of your friends' posts (newsfeed)
Let's say this is a reasonable list of initial requirements. First, confirm with the interviewer that they make sense and afterward start asking more detailed questions, such as:
- Interviewee: Can the posts have images and videos in them or just text?
Interviewer: Assume only text for now and we'll look at other media types later. - Interviewee: Can a user comment on another comment?
Interviewer: No, our system supports a single level of comments. - Interviewee: How are the posts in the newsfeed chosen?
Interviewer: The posts are the top most recent posts from the user's friends. - Interviewee: What happens when the user scrolls past the initial posts in their newsfeed?
Interviewer: The application should be able to load more posts.
These are just a few examples of the questions you might be asking. There are of course a lot more, but you don't want to spend 20 minutes on them. Think about what might impact your design and focus on those areas. You'll find that the interviewer wants to keep things simple at this point, so don't try to over-complicate things yourself because again, you won't have time for them.
2. Non-functional Requirements - 5 minutes
While still technically in the requirements part of the talk, I like to separate these two because the dynamic changes a bit. The biggest mistake I see people make here is making a lot of assumptions instead of asking questions. You don't know the characteristics of the system that the interviewer has in mind, so ask. I see a lot of folks assume the systems need to scale to billions of users when maybe the interviewer is thinking of a much smaller system.
In my opinion, there are a few universal questions that can help you get a clear picture of what you're needing to design.
- Availability vs. Consistency. Assuming that network partitions are a given, find out what level of consistency does your application need to support. Often it's eventual consistency, but sometimes it might require strict consistency for some parts (payment services for example).
- Number of users. You care about DAU (daily active users) or MAU (monthly active users).
- Distribution of users. You might also care about the geographic distribution of users, if they're located in one or more regions around the world.
- Traffic. Find out what is the expected volume of traffic (avg and peak). This is usually expressed in requests per second, minute or day.
- Access pattern. Understand if the system is more read-heavy than write-heavy or vice-versa. It can drastically influence your design.
- Data retention. It's usually good to know for how long you need to store the data in the system and what are the expectations in fetching older data sets.
Let's assume you asked these questions and the answer is that our system is eventually consistent, with 1B users around the world that produce 500k posts/min. Let's also assume that the read:write ratio is 10:1 and we need to store post data for at least 10 years.
In addition to these, we might ask some product questions for our specific use-case, such as:
- Interviewee: How many friends does a user have on average?
Interviewer: 1000. - Interviewee: How many posts does the newsfeed display at a time?
Interviewer: 20. - Interviewee: How long till a new post from a friend appears in the user's newsfeed?
Interviewer: Between 1-10 minutes. - Interviewee: What is the maximum length of a post?
Interviewer: 1000 characters.
3. High-level Design - 15-20 minutes
This step is where you use all the information collected so far in terms of requirements to draft a proposal for the design of the system. Before going into this, I want to mention something that I see some candidates do, namely back-of-the-envelope calculations. I won't get into detail about the specifics, but here is an example of the thought process behind it.
The reason I bring this up is that I believe you shouldn't bother with it as part of a regular system design interview. While it can be useful to showcase your estimation skills, it's not worth the time investment. I saw a few candidates writing down the types (int, string) of data model of the system in order to precisely estimate the storage size. You don't need that level of detail! And you can end up spending precious minutes just to say that the system needs to store 125TB of data. The interviewer doesn't usually care about specific numbers, just saying that it's going to be in the 10TB+ range or 1PB+ range is enough. If the interviewer wants more detail, they will ask you. Coming up with these precise numbers doesn't really highlight your system design skills, which is what this interview is all about.
To be successful in this step of the discussion, you need to know the fundamental building blocks of large-scale distributed systems. You don't need to be a master at all of them, but understanding how they can be used to build a system definitely helps. Here are a few areas that I recommend you familiarize yourself with:
- APIs - HTTP(s), GraphQL, gRPC etc.
- Databases - SQL, NoSQL (key-value, document, wide-colum, graph). Know their strengths and where one is more appropriate.
- Load balancers - Every distributed app needs a load balancer. Understand common load balancing protocols.
- Caching - Know when to use it and where. Understand different eviction policies (LRU being the most common) and more importantly, cache invalidation (a very hard problem).
- Message queues - Many event driven systems use message queues to optimize for async processing.
- CDNs - Often used in multi-region setups, CDNs are very useful for serving static content.
- Cloud services - Get familiar with at least one cloud provider (AWS, Azure, GCP) and their basic services (blob storage, compute units, managed database services, auth systems etc.)
- Vertical vs. Horizontal scaling - Know what is the limit of vertical scaling and understand common patterns for horizontal scaling.
- Sync vs. Async processing - Understand when each needs to be used and what are some anti-patterns of each.
- Public vs. Private clouds - Consider when you might use a private cloud (security, compliance) and what are the disadvantages vs. a traditional public cloud (upfront cost, maintenance etc.).
- Distributed sytems patterns - Understand some of the widely used patterns such as retries, throttling, circuit breaking etc.
So let's jump into our design. One thing that I like to do is get the boilerplate out of the way. By this I mean things like multi-region availability, client interaction with our services and authentication and authorization. It's not that these topics are not important - they are. But they are well researched and understood topics and the interviewer really cares about the specifics of the system you need to design (in our case Facebook). You should mention them and ask if the interviewer wants to get into details. More often than not, you can quickly move past them and get to the heart of the problem.
Here is how this looks in our case:
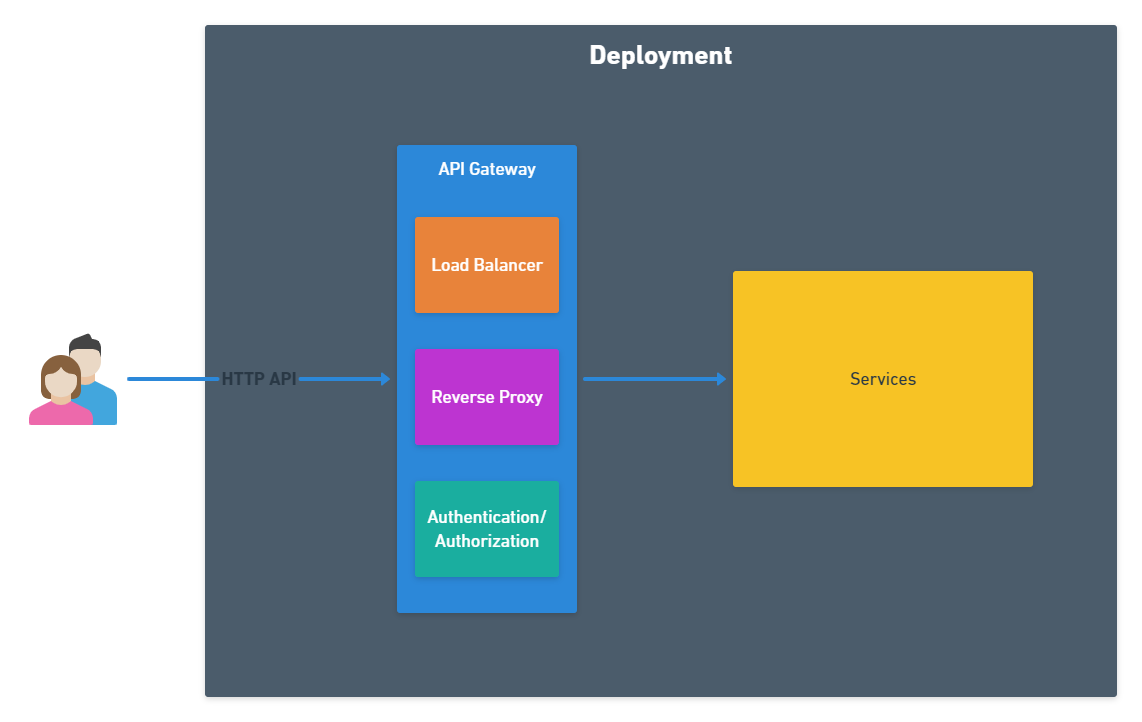
We know that the system needs to be deployed in multiple geographic regions, but we're focusing on a single deployment for now. Our system will need an API powered by multiple web-servers. This API will hit what I like to all an API Gateway. This is an umbrella term for multiple auxiliary services such as load balancing, reverse proxying and auth. Again, it's not that these components are not important, but we want to get to the meat of our system.
The interesting design will happen inside the Services box. This doesn't mean that each system needs to have a service oriented architecture (SOA), but it's very useful to think in terms of individual services, even if we end up starting with a monolith in practice. Oftentimes in system design problems you will use a micro-service architecture, so I highly encourage you to read more about it.
User Management Flows
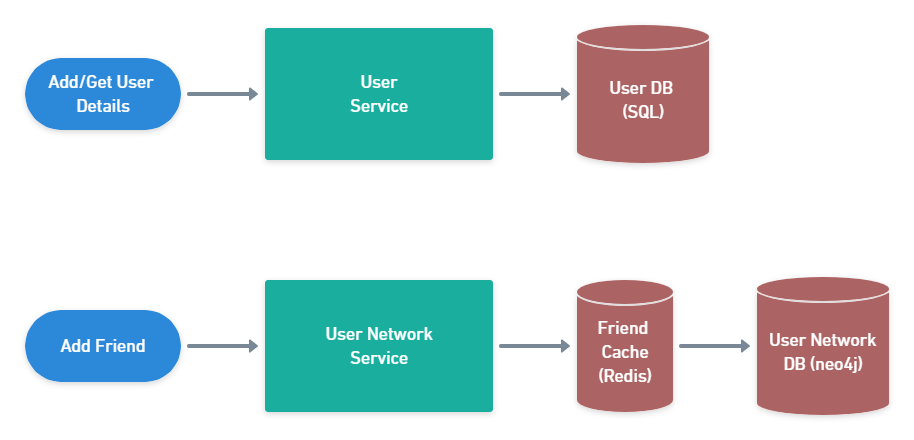
Let's start with user management. Whenever a new user joins our platform or we want to retrieve data about a specific user, the API will call a User Service. This service exposes an API to save and fetch data about a particular user. It uses a sharded SQL database to store the user details. Why SQL you ask?
- Because the data tends to be very structured, each user has the same type of information.
- We don't expect a large volume of reads/writes to the DB, so performance is not an issue.
- ACID compliance is very useful here, as we want to reflect any changes immediately.
Of course you can use a NoSQL database just as well, but this is a case where SQL is more than adequate. The only downside is that we need to maintain the sharding at the application level. If performance really becomes an issue, we can always add a caching layer in front.
For adding friends or retrieving the list of friends for a user, we have a separate User Network Service. As the data we need to store here is significantly greater than the User Service and the access pattern is different (a user will search through their friends list more often than checking their own information), we need a different database, particularly one optimized for graph lookups. That's why in this case I'm proposing a Graph DB like neo4j which is well suited for this. We also want a cache in front of this DB, because we anticipate a high number of reads for friends of a user (more details below). For the caching part we can use pretty much anything, though Redis is an industry standard.
Post Flow
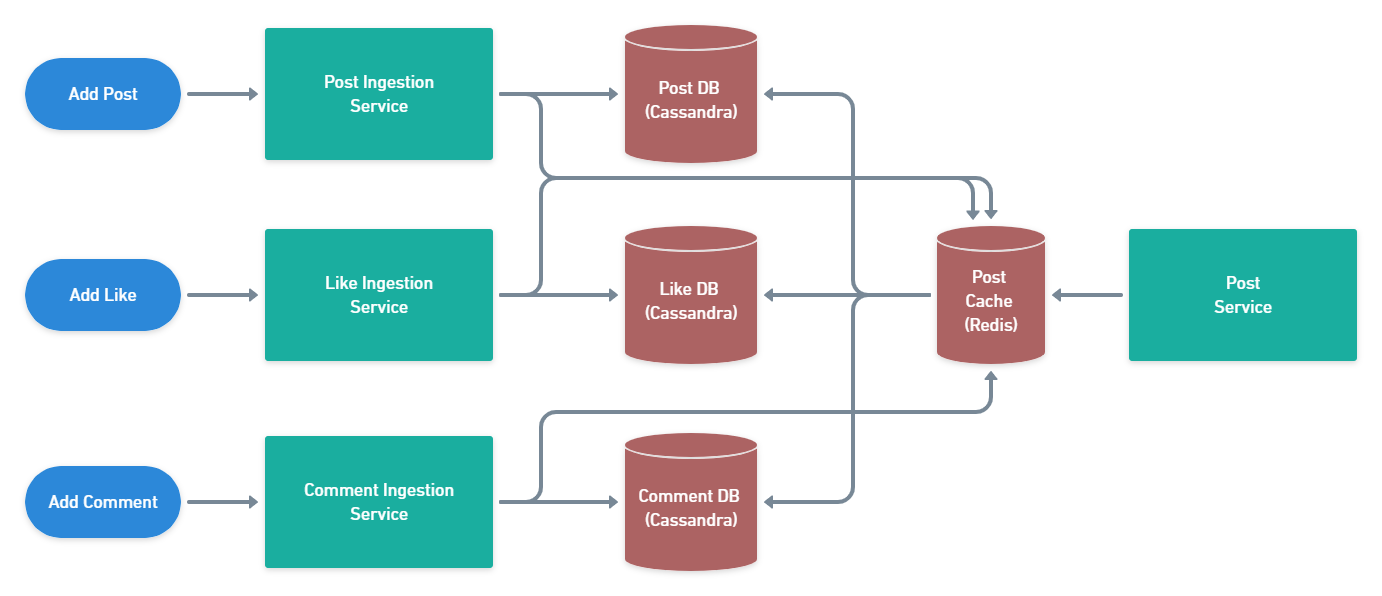
Getting to post creation, we'll have different ingestion services that handle adding of new posts, likes to posts and comments to posts. For the DB in all three we're going for a NoSQL approach here, specifically Cassandra. Why? Cassandra has a lot of strong points, but here we're interested in high write performance and horizontal scalability. Likes and comments can be at least one order of magnitude greater than the number of posts themselves, so Cassandra really shines here. It's consistent hashing mechanism ensures high availability with minimal overhead. We can also tune its consistency level to our needs in terms of number of replicas that need to be in sync.
For getting aggregate information about a post (content, likes, comments) we'll make use of a separate Post Service that is powered by a Redis cache. This cache will be maintained by each ingestion service. Depending on the TTL and invalidation policies that we chose, we can optimize for better read performance vs. showing the most up to date information about posts.
Newsfeed
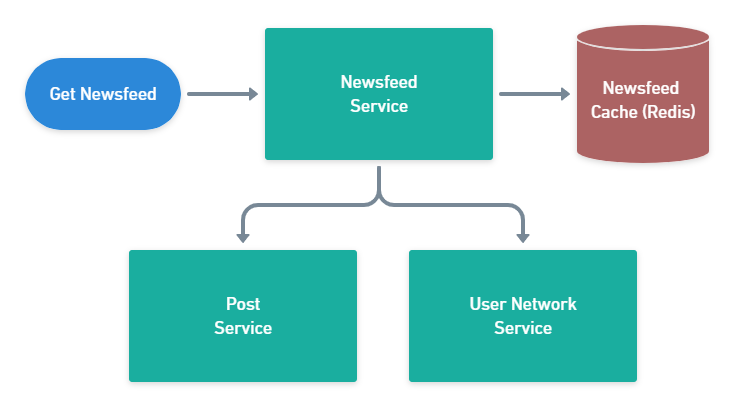
For the newsfeed part, we're going to need a different service to interact with the User Network Service and the Post Service to get the list of friends for a user and then get their most recent posts. As we can afford some delay in refreshing the newsfeed, we can cache all of that information into Redis. This begs the question of how is that cache going to be populated? We'll explore this below.
There's a lot more than we can talk about at this stage, such as real-time analytics, user preferences and how that relates to posts etc. Even if you are tempted to cover as much ground as possible, try to stop after 15 minutes maximum and get the buy-in of the interviewer. Make sure they are onboard with the design before diving into more details. If they want you to include anything else in the design, they'll mention it, otherwise assume the initial proposal is good enough and move on to detailing at least one flow.
4. Deep Dive - 15-20 minutes
After you finished with the initial design it's a good time to ask the interviewer if there's one specific area that they want to understand in more detail - usually they have at least one or two in mind.
For our purposes let's assume the most interesting problem is that of newsfeed generation and retrieval, so that's what I'll be focusing in the next section.
First of all, there's two main ways of getting the newsfeed when a user opens the app:
- At read-time, by searching the list of friends for the user, getting the most recent posts from each, merging that in memory and returning the result. This is very computationally expensive to do every time a user looks at their newsfeed. Sure we can cache the result after the fact, but regenerating it means doing the same lookup process even if just a single post is different.
- At write-time, when a new post gets added. Here we're trading some performance at write-time to make our reads much faster. But if we want to make this work, we need a fast way of maintaining the newsfeed for each user in (almost) real-time. This is the option that we're going to explore next.
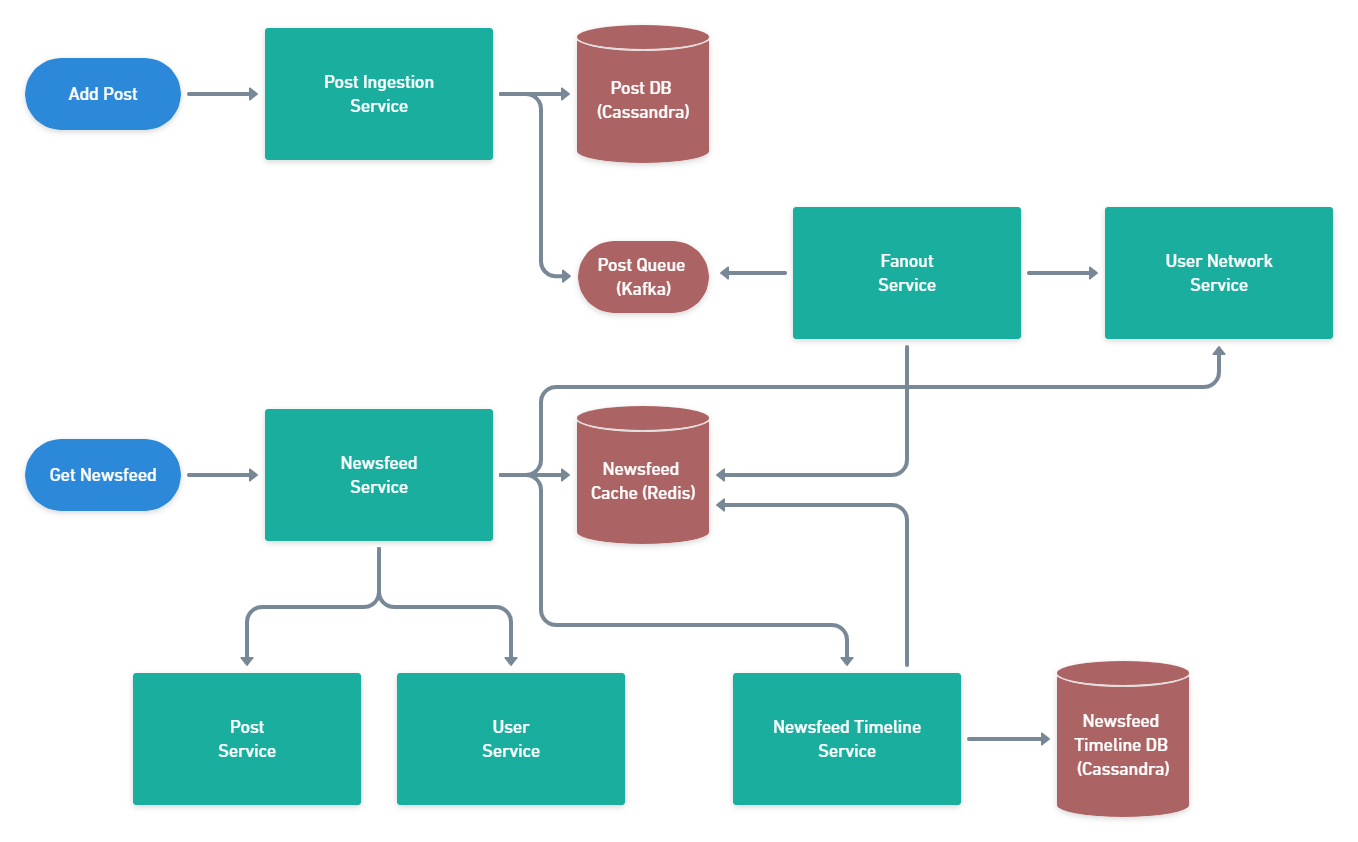
First, let's see how the newsfeed gets created. When a user adds a new post, besides just storing it into the DB, we also publish an event saying that User X just added Post Y at some timestamp. Any distributed message queue will do here, I'm choosing Kafka this time. Why Kafka? Because it's a very mature technology, easily supports our scale and has some features such as keyed partitioning that are a big help in dealing with concurrency issues.
The messages from this queue are consumed by a Fanout Service, whose job is to update the newsfeed for all users that might be interested in seeing this new post - in our case all of them. It does this by querying the User Network Service to get the list of friends for this particular user. It then looks up the Newsfeed cache for all the generated timelines of these friends and updates them to contain this new post. Think of entries in this cache as (user_id, list_of_post_ids, last_updated_timestamp). We just store the IDs of posts here and use the Post Service to get their full content. We also use the User Service to get user details related to the posts - name, status etc.
What about scrolling past the initial newsfeed? What do we do then? Well we can't keep the complete timeline for all users in Redis, that would be too much. What we can do is use two-layer approach.
- Store the newsfeed of each user for 24h in the cache.
- At regular intervals, read all newsfeed data, store it in a separate (slower) storage (Cassandra) and clear the cache. This is done by the Newsfeed Timeline Service.
In this way we ensure that our cache doesn't get too large and it gives us a nice trade-off between fast retrieval of data for recent posts and cost optimization for older posts. If the Newsfeed Service detects that the user is requesting newsfeed data that is not present in the cache (based on the last_updated_timestamp), then it will query the Newsfeed Timeline Service.
This approach works very well for regular users that don't have a lot of friends. But what happens when we get to famous users, that can get up to millions of friends? We could do the same thing as before, but there will be a big load on the system to constantly re-compute the newsfeeds for the friends of the famous user. If we think that statistically there are few famous users, it makes sense to use a pull-model when it comes to seeing posts from celebrities.
In this model, whenever a newsfeed request comes in, the service first looks at the famous users which are friends with this user by calling the User Network Service. For those specific users, it queries the Post Service directly to get the latest posts and merges the result with whatever it gets from the cache. It then stores the new list back into the cache with a separate last_famous_timestamp. With this timestamp, we can control how often we want to fetch celebrity posts and embed them into our users' newsfeed.
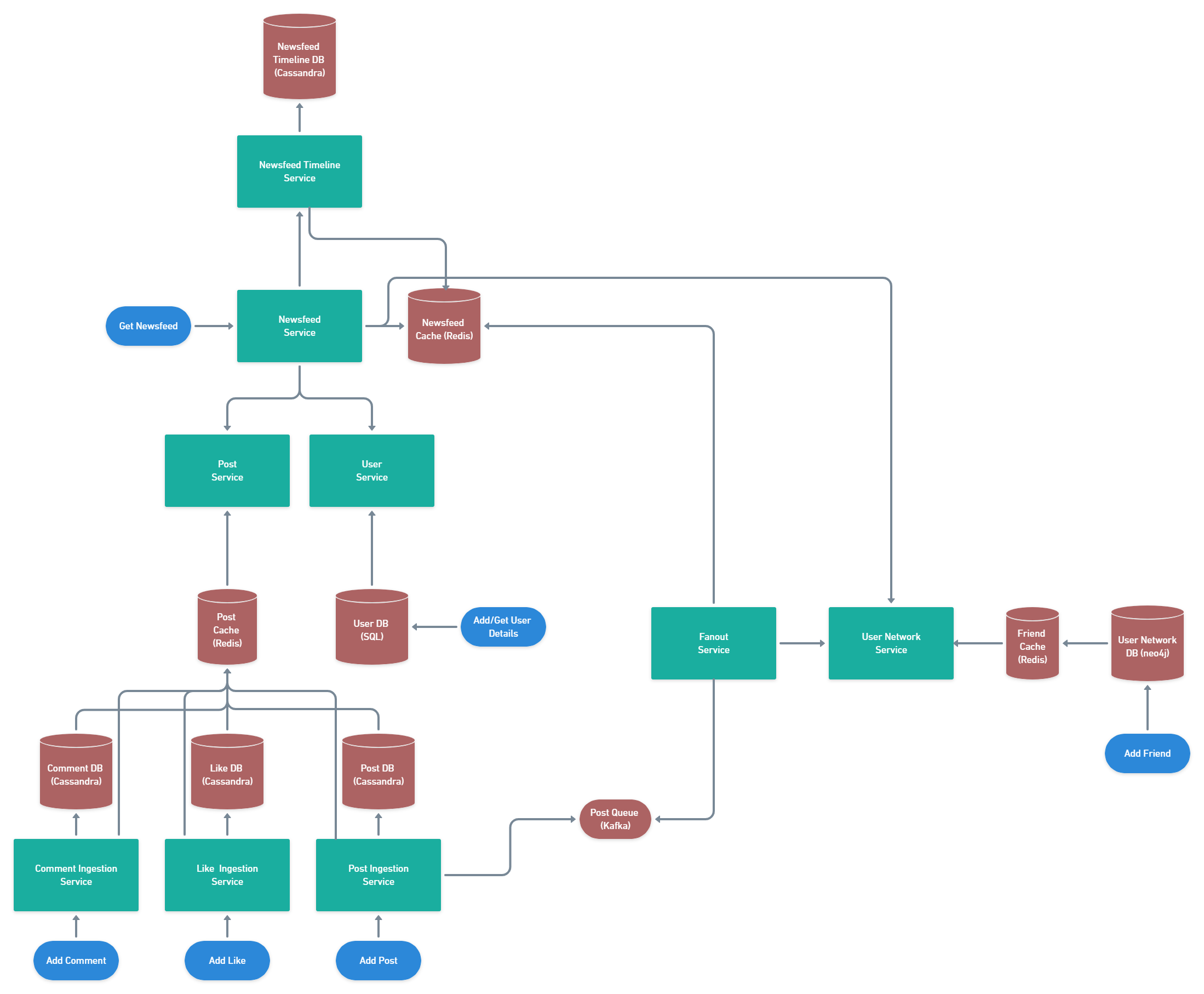
Complete design
For reference, here is the full design that sums up all the parts that we've previously discussed. At the end of this step you should have a clear image of the design of your system and how it maps to the original requirements.
5. Follow-up - 5-7 minutes
Of course we only covered a small part of how a system like this should be designed. The interviewer usually will interrupt you at different points to ask follow-up questions, it doesn't necessarily need to be after you've drawn out the complete diagram.
Here are some interesting questions that could come up in this discussion:
- How do you avoid hot shards?
- We've only mentioned Cassandra and Redis as storage solutions, but with partitioning usually comes the issue of hot partitions/shards. The key here is to design good IDs for your models.
- What if we wanted to add photos and videos to posts?
- The design wouldn't change much, we would need a separate file storage (S3) accessible by the Post Service and possibly a CDN to quickly serve that static content.
- How would you change the system to allow replies to comments?
- Again the overall flow would remain the same, but the data model for comments would change to include a link to its parent comment (if the comment is a reply). It might also be useful to keep the replies sorted by timestamp.
- What if we wanted to change the newsfeed algorithm to display relevant posts instead of just the newest?
- We would first need to define what relevant means, but assume it's an heuristic that takes into account the popularity of posts, category (nature, sports etc.) and interaction between users (if I chat with some user a lot, I might want to see their posts more often). For all of this we need a separate analytics service that consumes data from the same Kafka topic for newly added posts. This service would make user of different ML models to classify posts based on these indicators and would later on integrate with the Fanout Service to determine the order of the posts in the newsfeed.
Besides these, the interviewer might ask you more generic questions i.e. not specific to this particular system, such as:
- How do you handle a spike in user traffic?
- How do you handle the case where a service fails?
- What metrics would you track for this sytem?
- How would you deploy the application to multiple geographic regions?
For all of these questions, you're not expected to start drawing out the new components and change your proposal. The interviewer is mainly interested to see if you really understand your proposal and how it can be extended. If you have time to change things around to reflect the new behavior, by all means do it, you're going to score extra points for that. We won't cover these potential follow-ups in this article, there are plenty of online resources that you can use to explore further.
What not to do
Knowing some anti-patterns or what not to do during these interviews is also valuable in maximizing your chances of success. Here are a few from my observations and experience:
- Not asking enough questions. It not only leads you to potentially build something else than what the interviewer wanted, it's also a sign that you don't understand how collaboration and curiosity are key elements when building products.
- Spending too much time on the requirements. You don't need to explore every possible feature the system might have, you won't have time to design it anyway.
- Back-of-the-envelope calculations. I've mentioned this before and I'll say it again - don't do it, the interviewer doesn't care usually.
- Diving deep in one are from the start. I see this in candidates all the time. They get to the API part and then they start talking about HTTP methods, versioning, error codes etc. Don't do this! There's a time and place to get into this sort of detail (if the interviewer asks you) but that time is not at the beginning of the interview. First get a high-level picture of the system.
- Focusing on technology. Some people are so familiar with a specific tech stack, that they will try to model everything using that stack. One example is AWS services. You don't need to say that you're going to use EC2 instances or RDS databases, try to keep it more abstract. This proves to the interviewer that you can detach yourself from specific terms and concepts and explain your solution in terms that are widely understood.
- Not making any pauses. Don't talk for 30 minutes and then ask the interviewer for feedback. Try to make it an interactive conversation, where you're the one leading but check in from time to time with your interviewer. Keep them enganged in your thought process and let them hint you in the right direction.
- Rigid design. Think about the responsibilities of different components in your system. If you couple things too much from the start, you'll have a very hard time on follow-up questions that might require some rewiring.
- Too complex designs. Yes, there is such a thing. While you should have enough detail in your design to convey your ideas, you don't need to go overboard and start drawing out how you'd handle rate limiting, retries etc. In some cases you might need to but more often than not, simply mentioning these concepts and how you'd apply them is enough.
- Diving too deep. Yes, there is such a thing also. I see candidates start drawing out full database schemas with columns, keys, conditions etc. While certainly valuable for visibility, you don't need to map out every single property. Just mention the important ones, such as IDs and references to other entities. Or mentioning different bloom filter implementations in the context of caching. While you might score some bonus points from time to time, it's not that important unless the interviewer specifically asks you to optimize the caching layer.
Closing Thoughts
High-level system design is tough and requires both skill and experience. It's very hard to fake experience, but as with any skill, you can get much better at this with practice.
I can't stress this enough - practice! I know you think designing Uber or WhatsApp looks simple on paper, but start working on them and you might find yourself getting stuck quickly. This is the power of practicing. You don't need to design super fancy systems, even apparently simples ones such as Facebook can have many, many layers of complexity.
Best of luck in your upcoming system design interviews!
Read next
So you want to be an engineering manager?
After a few years as a software engineer, I was contemplating what direction to take my career in. In my mind, there were two options - manager or technical architect. I know architect is a vague term, but for me it represented the pinnacle of technical growth, someone that designs

Improving coding interviews
I see this question all the time show up in one way or another - Why do we need coding interviews? Just to clarify, when I'm speaking about coding interviews, I'm specifically referring to an algorithms & data structures type of interview. I'm sure

The path to becoming a Senior Engineer
A natural step in the career of every software engineer is the transition to a senior role. Easier said than done, I see this step posing a challenge to a lot of engineers - that's why I want to write about what is expected from senior engineers and
